如何保存单个 PDF 页面( Windows、Mac 及 Python)
如何保存单个 PDF 页面( Windows、Mac 及 Python)
有时,我们只需要大型 PDF 文件中的某一页,比如说提交单张发票或者分享报告中的特定图表时。学习如何高效保存 PDF 单页可以为你节省大量的时间和精力。针对 Windows、macOS 及手机等不同平台,本文总结了四种实用方法,帮助你轻松导出单张 PDF 页面。
目录
- 在 Windows 及浏览器中使用打印为 PDF
- 使用 Google Chrome 或 Microsoft Edge
- 使用 Adobe Acrobat Reader
- 在 Mac 上利用预览保存 PDF 单页
- 使用在线 PDF 编辑器保存 PDF 文档
- 利用 Python 自动化保存 PDF 中的单页
- 方法对比表格
在 Windows 及浏览器中使用打印为 PDF
从 PDF 中保存单页最常用的方法是打印功能。这种技术本质上是将你选择的 PDF 页面打印成一个新的、体积更小的 PDF 文件。根据你所使用的软件不同,比如浏览器或者是 Adobe,保存 PDF 单页的操作步骤在界面上会略有差异。
使用 Google Chrome 或 Microsoft Edge
浏览器通常是完成这个任务的首选工具,因为无需安装额外的软件,并且浏览器的操作页面简单易懂,非常直观。下面我们以 Chrome 浏览器为例,详细讲解如何保存单张 PDF 页面。
- 第一步: 将你的 PDF 文件直接拖入 Chrome 浏览器的标签页中。
- 第二步: 按下 Ctrl + P 打开打印菜单。
- 第三步: 在目标打印机下拉菜单中,确保选中了 另存为 PDF。
- 第四步: 在“页面”选项下,选择 自定义 并输入你希望保留的那一个页码。
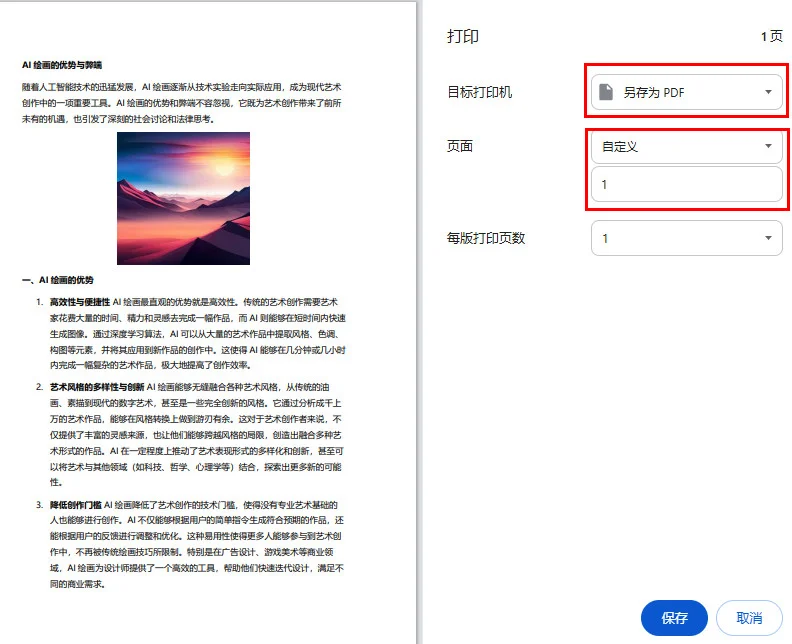
- 第五步: 点击蓝色的 保存 按钮并选择你的目标文件夹。
使用 Adobe Acrobat Reader
作为专业的 PDF 处理工具,Adobe Acrobat 能够轻松应对各类复杂的文档任务。如果想从中提取单页,最直接的方法依然是调用其内置的打印引擎。相比浏览器,它在参数调节和输出精度上提供了更专业的控制。
- 第一步: 在 Adobe Acrobat 或 Reader 中打开你的文档。
- 第二步: 点击打印机图标或按下 Ctrl + P 打开打印对话框。
- 第三步: 从顶部的打印机菜单中,选择 Adobe PDF 或 Microsoft Print to PDF。
- 第四步: 在待打印页面部分,选择 页面 单选按钮并输入你的目标页码。
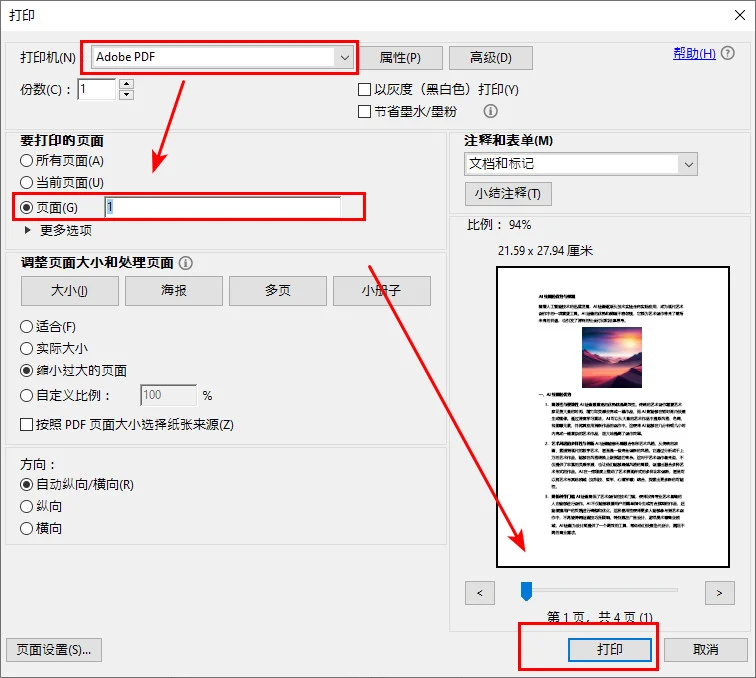
- 第五步: 点击 打印,当弹出另存为窗口时,为你的文件命名并保存。
提示:你也可以通过删除多余页面来实现提取 PDF 单页,具体操作步骤可以查看这篇关于如何删除 PDF 页面的详细教程。
在 Mac 上利用预览保存 PDF 单页
对于 Mac 用户来说,提取 PDF 单页的操作则更加简单。macOS 自带的预览应用原生支持各类 PDF 编辑任务,甚至无需借助虚拟打印机,只需通过简单的拖拽,就能快速完成 PDF 页面提取。
- 第一步: 双击你的 PDF 文件,默认情况下它会通过“预览”打开。
- 第二步: 如果你在左侧没有看到页面预览,请导航至 视图 > 缩略图。
- 第三步: 在侧边栏找到目标页面,然后只需将该缩略图直接拖动到你的桌面上。
- 第四步: 或者,选中缩略图,前往 文件 > 导出为 PDF,并在保存前确保勾选了 所选页面 选项。
使用在线 PDF 编辑器保存 PDF 文档
如果你习惯在手机或平板上办公,或者在处理其他任务时需要临时提取单页,在线 PDF 编辑器无疑是最佳选择。这类平台专门设有拆分或提取功能,不仅操作简便,而且几乎不限设备,随时随地都能上手。
第一步: 访问在线 PDF 工具,如 Smallpdf、iLovePDF 或 Adobe 的在线 PDF 服务。在本指南中,我们将以 Smallpdf 为例。
第二步: 点击 选择文件 或将你的文档拖入 Smallpdf 的 提取 PDF 页面 工具中。
第三步: 滚动浏览文档,并在你想要保存的特定页面上勾选复选框。
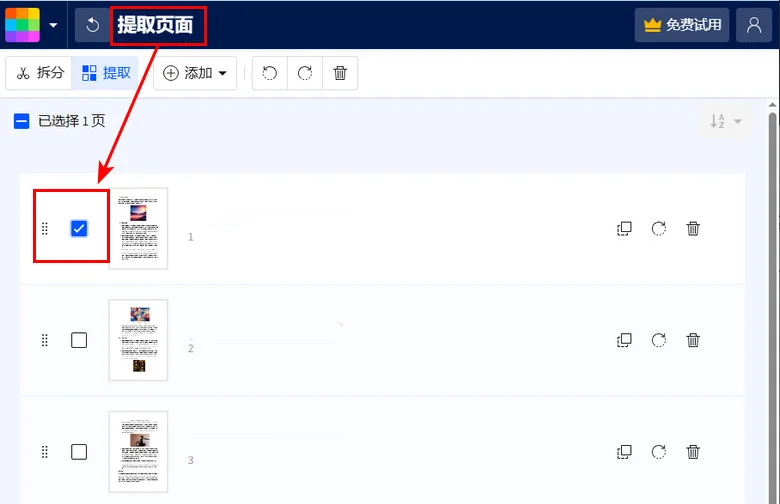
- 第四步: 点击 完成 按钮开始提取过程。
- 第五步: 处理完成后,点击 下载 按钮将新文件直接保存到你的设备上。
利用 Python 自动化保存 PDF 中的单页
前面我们介绍的方法大多适合用于处理单个 PDF 文件,但面对大量的 PDF 处理需求时,自动化脚本显然比手动操作更具优势。只需几行代码,你就能轻松完成数个文件的单页提取任务。为此,我们推荐使用 Free Spire.PDF for Python。作为一个功能强大的独立库,它可以在脱离 Adobe Acrobat 的环境下,高效实现 PDF 的创建、读取与编辑。
Free Spire.PDF for Python 保存 PDF 单页的核心逻辑是克隆特定页面到新的 PdfDocument 对象中。相比打印,这种提取方法能够保留文档的布局与矢量元素,避免了因图层扁平化导致的内容失真。
以下是如何安装 Free Spire.PDF 并启动 PDF 页面保存的方法:
- 第一步: 通过终端使用 pip install Spire.Pdf.Free 安装该库。
- 第二步: 加载你的源文档,并初始化一个新的空 PDF 对象作为单页容器。
- 第三步: 使用 PdfDocument.InsertPage() 方法将目标页面复制到新文件中。
- 第四步: 使用 PdfDocument.SaveToFile() 方法保存新的 PDF。
下面是一个简单的 Python 示例,展示了如何保存 PDF 文档的第一页:
1 | from spire.pdf import * |
原始文件与输出 PDF 文档的预览:
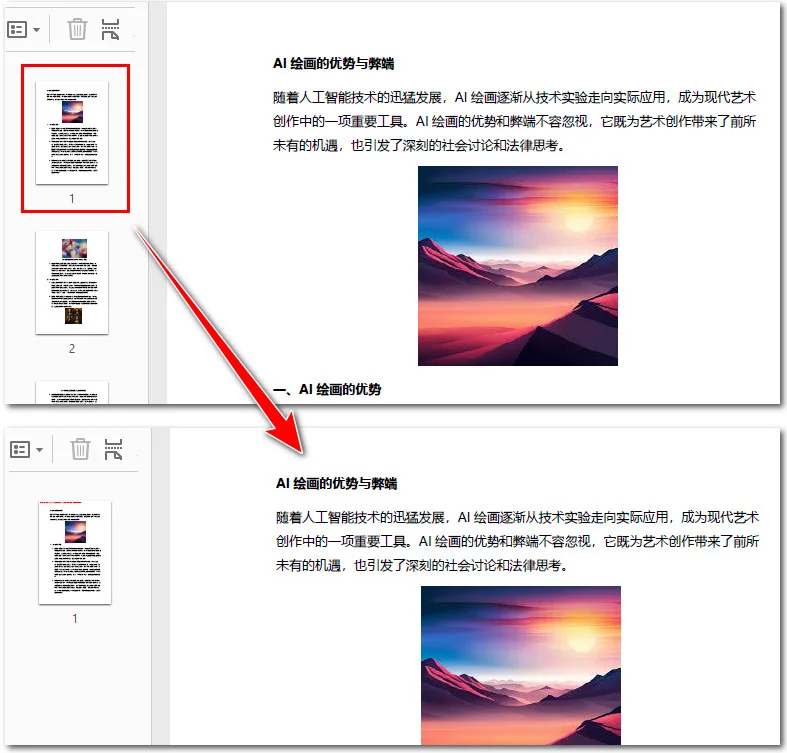
提示:除了提取特定页面,Free Spire.PDF for Python 还能实现更多高级自动化操作。例如,你可以通过编写简单的脚本快速检测并删除 PDF 中的空白页,从而进一步精简你的文档。
方法对比表格
面对以上四种各具特色的方案,哪一种才是你的最优选?下表综合对比了各方法的适用场景、核心优势及设备支持,助你一目了然地锁定最适合当前需求的处理方式。
| 适用场景 | 推荐方法 | 核心优势 | 设备与平台支持 |
|---|---|---|---|
| 快速处理单份文件 | 浏览器/Adobe 打印 | 操作零门槛,无需额外工具 | Windows / 通用浏览器 |
| macOS 深度用户 | Mac 预览 | 原生支持,拖放即提取,无损质量 | 仅限 macOS |
| 移动端或临时办公 | 在线 PDF 编辑器 | 随开随用,不占空间,功能多样 | 手机 / 平板 / 所有设备 |
| 海量文件批量处理 | Python 脚本自动化 | 极速处理,100% 精准且可重复 | 跨平台 (需 Python 环境) |
结论
总之,提取 PDF 单页远比想象中简单。对于追求便捷的普通用户,打印为 PDF和在线工具足以应对绝大多数日常场景;而 Mac 用户凭借系统自带的预览功能即可实现快速操作。如果你正面临海量的文档处理需求,那么基于 Python 的自动化方案无疑是提升效率的最优解。










