PDF 表格转 CSV:手动、在线与自动化实现方法
PDF 表格转 CSV:手动、在线与自动化实现方法
在报表制作、数据分析以及系统数据集成等场景中,将 PDF 文件中的表格转换为 CSV 格式是一项非常常见的需求。相比 PDF,CSV 文件结构简单、通用性强,也更适合后续的数据处理和自动化流程,当表格数据需要被重复利用时,CSV 的实用性往往远高于静态的 PDF 文件。
然而,在实际操作中,PDF 表格转 CSV 并不是一件“直接导出”就能解决的事情。PDF 的核心设计目标是还原视觉排版效果,而不是表达数据的逻辑结构。也就是说,一个在页面上看起来行列分明的表格,在 PDF 内部并不一定以真正的“行”和“列”形式存在,而可能是以坐标位置排布的文本或形状,这正是许多简单转换方法效果不理想的根本原因。
因此,本文将聚焦于实际可行的 PDF 表格转 CSV 方案,从真实使用角度出发,介绍几种最常见的方法及其使用步骤,分析它们的优缺点,并说明各自适合的使用场景。
内容概览
- PDF 表格转 CSV 的常见实用方式
- 方法一:使用 Acrobat 导出 PDF 表格
- 方法二:使用在线 PDF 表格转 CSV 工具
- 方法三:使用 Python 程序化提取 PDF 表格
- 方法选择与总结
- 常见问题
PDF 表格转 CSV 的常见实用方式
在实际工作中,将 PDF 表格转换为 CSV,通常会采用以下三类方式之一:
- 通过 PDF 转电子表格工具(如 Acrobat) 进行导出
- 使用 在线 PDF 表格转 CSV 转换工具
- 通过 Python 等编程方式进行程序化提取
需要特别说明的是,简单的复制粘贴方式并不在本文讨论范围内。这类方法通常会破坏表格结构,最终得到的只是零散文本,后续还需要大量手动整理,实用价值较低。
方法一:使用 Acrobat 导出 PDF 表格
对于偏好桌面工具、且需要人工检查结果的用户来说,使用 Acrobat 将 PDF 导出为电子表格,再保存为 CSV,是一种相对稳妥的选择。
适合使用该方法的情况
- PDF 为文本型文件(非扫描件)
- 表格结构较为规范,行列边界清晰
- 可以接受一定程度的人工校对和调整
使用 Acrobat 的典型操作流程
使用 Acrobat 打开 PDF 文件
选择 导出 PDF,并将导出格式设置为 电子表格

将文件导出为 Excel 格式
检查表格结构,并根据需要进行调整
将 Excel 文件另存或导出为 CSV 格式
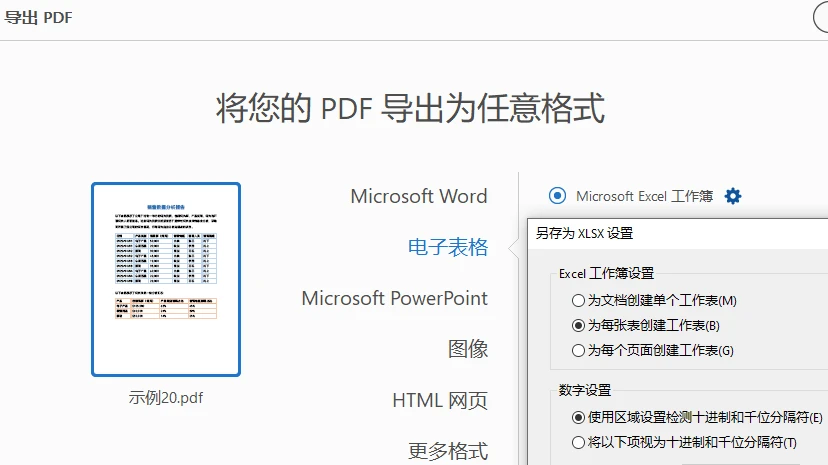
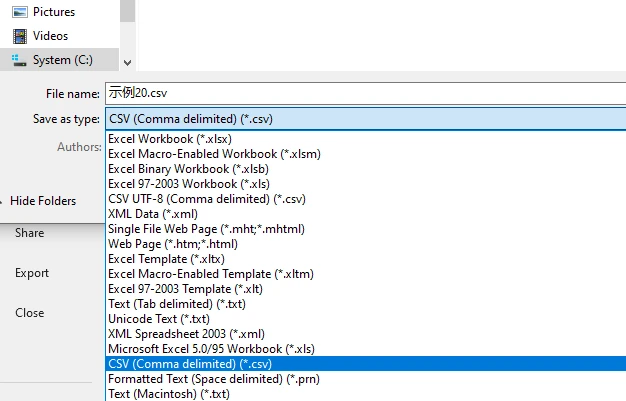
在很多情况下,这种方式比直接复制粘贴更容易保留原有的行列结构,尤其适用于单页或格式统一的表格。
这种方法的局限性
- 复杂或跨页表格可能被拆分到多个工作表中
- 合并单元格在转换为 CSV 时容易导致列错位
- 通常需要手动清理数据
- 不适合批量处理或自动化场景
因此,该方法更适合偶尔使用、并且需要人工确认结果的情况,并不适合作为长期或规模化的解决方案。
如果你希望寻找 Acrobat 的免费替代方案,可参考:如何免费将 PDF 转换为 Excel。
方法二:使用在线 PDF 表格转 CSV 工具
在线转换工具因无需安装、上手快,常被用于临时或一次性的转换需求。
适合在线工具的场景
- PDF 中包含可选中文本(非扫描 PDF)
- 表格结构相对简单
- 转换文件数量较少
在线 PDF 表格转 CSV 的常见流程
大多数在线工具的操作流程大同小异(以下以 Convertio 为例):
打开在线 PDF 转 CSV 工具页面
上传包含表格的 PDF 文件
如工具支持,可设置页码范围或表格识别选项
启动转换过程
下载生成的 CSV 文件


对于结构简单的 PDF,这种方式通常可以在较短时间内生成可用的 CSV 文件。
使用在线工具时需要注意的问题
- 当列间距不稳定时,容易出现列错位
- 许多工具会导出整个 PDF 内容,而不仅限于表格
- 输出质量高度依赖原始文档布局
- 可能存在文件大小限制或数据隐私风险
因此,在线工具更适合作为一种便捷选项,而不适合作为稳定、可复用的解决方案。
方法三:使用 Python 程序化提取 PDF 表格
当对转换结果的准确性、一致性或自动化程度有较高要求时,程序化提取通常是最可靠的选择。
程序化提取的优势
- 可以按页精确处理表格数据
- 能稳定处理跨页表格
- 相同逻辑可复用于批量处理任务
- 转换结果可复现、便于验证
这种方式常用于数据管道、报表系统以及需要大规模处理 PDF 的后台服务中。借助 Spire.PDF for Python,开发者可以直接提取 PDF 中的表格结构,并将整个过程自动化。
PDF 表格转 CSV 的典型程序化流程
一般来说,程序化提取会包含以下步骤:
- 加载 PDF 文档
- 按页遍历 PDF 内容
- 识别页面中的表格结构
- 按行和列提取结构化数据
- 必要时对文本内容进行规范化处理
- 将结果写入 CSV 文件
示例:使用 Python 将 PDF 表格转换为 CSV
在运行示例代码前,请先安装所需的 PDF 处理库。
1 | pip install spire.pdf |
安装完成后,即可使用 Spire.PDF for Python 提取 PDF 表格并导出为 CSV。
1 | import os |
下图展示了 PDF 表格成功转换为 CSV 后的示例结果:
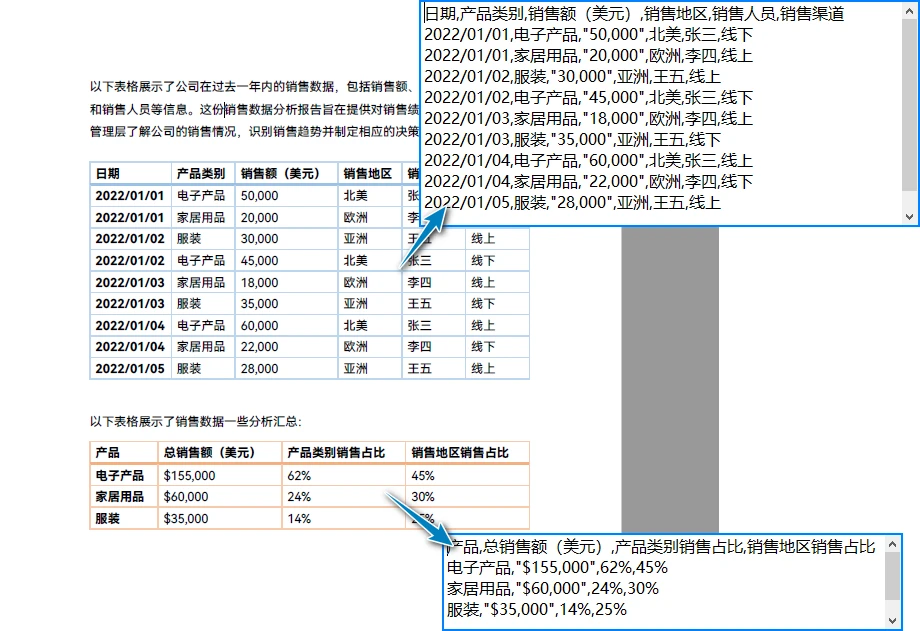
实现思路说明
该方案的核心在于直接提取表格结构本身,而不是通过字符位置去猜测布局:
- 单元格级提取,确保行和列作为结构单元被准确保留
- 逐页处理,避免跨页表格被错误合并
- 显式文本规范化,处理 PDF 中常见的连字和私用区字符问题
- 直接写入 CSV,避免中间格式引入额外干扰
因此,生成的 CSV 文件更加稳定,更适合自动化使用。更详细的操作说明可参考:PDF 表格提取完整指南。
注意事项
- 连字和私用区字符
在部分英文或混合语言的 PDF 文件中,可能会遇到连字(ligatures)或私用区字符(PUA)导致的文本异常。这时需要对提取到的数据进行特殊字符规范化处理,例如:
1 | def normalize_text(text: str) -> str: |
对这类字符进行规范化处理可以避免查看 CSV 文件时显示为乱码或其他字符。
- CSV 编码处理
CSV 编码是一个经常被忽视但非常关键的细节,尤其是在提取包含中文字符的数据时:
- 当 CSV 中包含非 ASCII 字符时,直接用 Excel 等编辑器打开可能出现乱码
- 将 CSV 保存为 UTF-8 with BOM(UTF-8-SIG),可以避免手动导入步骤并确保字符正常显示
参考:1
2
3with open("output.csv", "w", newline="", encoding="utf-8-sig") as f:
writer = csv.writer(f)
writer.writerows(rows)
方法选择与总结
在实际应用中,PDF 表格转 CSV 通常可以归结为三种方案:
- Acrobat 导出:适合偶发需求,需要人工校验结果的场景
- 在线转换工具:适用于结构简单、一次性的快速转换
- 程序化提取:在复杂表格、跨页数据或自动化流程中最为稳定可靠
最终选择哪种方式,关键并不在于工具本身,而在于转换后的数据将如何被使用。
常见问题
扫描版 PDF 表格可以直接转换为 CSV 吗?
不可以。扫描版 PDF 需要先进行 OCR 文字识别,才能进一步提取表格数据。可参考:使用 Python 从图片中提取文本。
相比 Excel,CSV 是否更适合保存 PDF 表格数据?
CSV 更简单,更适合自动化处理;Excel 则更适合人工查看和编辑。
Python 适合批量处理 PDF 表格吗?
是的。Python 因其灵活性和良好的可读性,常被用于大规模、自动化的 PDF 表格提取任务。










