如何删除 PDF 中的空白页(手动+自动)
如何删除 PDF 中的空白页(手动+自动)
空白页是 PDF 文档中常见的问题。它们通常在从 Word 或 Excel 导出文件、扫描纸质文档,或以编程方式生成报告时出现。虽然空白页看起来似乎无伤大雅,但它们可能会降低文档质量、增加文件大小、浪费打印资源,并使文档显得不够专业。
根据具体使用场景,删除 PDF 中的空白页可以通过手动或自动化方式完成。手动方法适合小型文档和一次性操作,而自动化解决方案在批量处理、重复性工作流或系统级集成中更加高效。
在本文中,我们将详细介绍这两种方法。首先,我们将演示三种手动删除 PDF 空白页的方法;随后,将展示如何使用 Python 自动检测并删除空白页,并提供一个基于 Spire.PDF for Python 的完整实用解决方案。
方法预览:
- 方法 1:使用 Adobe Acrobat 删除空白页
- 方法 2:使用在线 PDF 工具删除空白页
- 方法 3:通过预览(macOS)删除空白页
- 方法 4:使用 Python 自动删除 PDF 中的空白页
什么是 PDF 中的“空白页”?
从技术角度来看,PDF 中的“空白页”并不一定是真正意义上的空白。虽然在视觉上它看起来是空的,但实际上仍可能包含不可见对象、空容器或白色图像。
在实际应用中,一个空白 PDF 页面可能:
- 不包含任何文本对象
- 不包含任何图像
- 视觉上为空白,但仍包含不可见元素
- 在转换过程中产生排版异常
这一点在自动化删除过程中尤为重要,因为仅依赖文本检测往往无法准确判断页面是否为空。
第 1 部分:手动删除 PDF 中的空白页
手动方法最适合文件数量较少、且需要人工确认准确性的场景。这些方法无需编程知识,用户可以在查看文档后有选择地删除页面。
方法 1:使用 Adobe Acrobat 删除空白页
Adobe Acrobat提供了一种专业且高度准确的 PDF 页面管理方式。其基于缩略图的界面允许用户直观查看所有页面,并精确删除空白页。
详细步骤
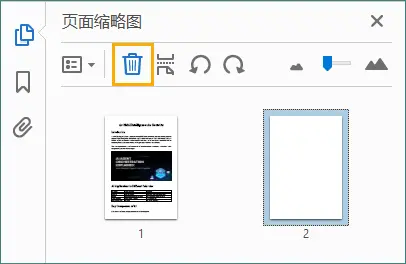
- 在 Adobe Acrobat 中打开 PDF 文件。
- 打开“页面缩略图”面板。

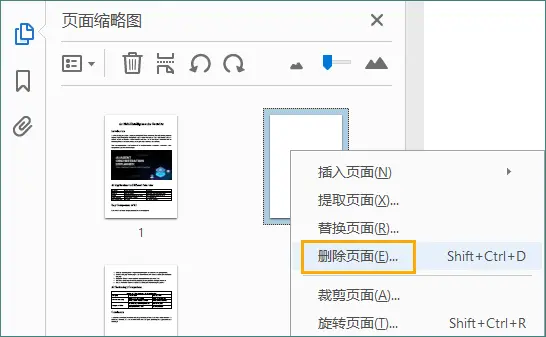
- 选择要删除的空白页,然后点击“垃圾桶”图标。
或者,右键单击所选页面并选择“删除页面…”,可删除当前页面或一段连续页面。 - 保存更新后的 PDF 文件。

优点
- 通过视觉确认实现高准确性
- 能很好地处理复杂布局和大型 PDF
- 适合专业或面向客户的文档
缺点
- 需要付费的 Adobe Acrobat 许可证
- 在处理大量文件时较为耗时
方法 2:使用在线 PDF 工具删除空白页
在线 PDF 工具无需安装软件即可快速删除空白页。大多数平台支持上传 PDF、预览页面,并直接在浏览器中删除不需要的页面。
详细步骤
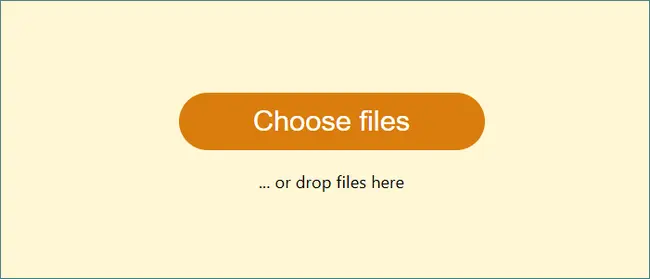
- 打开一个在线 PDF 编辑网站(例如:PDF24)。
- 点击“Choose files”或将 PDF 文件拖放上传。
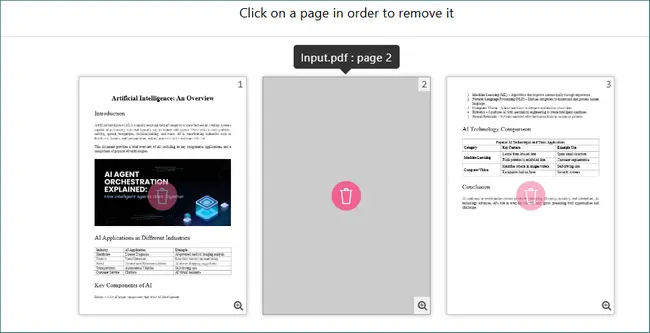
- 进入预览或页面管理模式,选择并删除空白页。
- 点击“Create PDF”(或类似的确认按钮)应用更改。
- 下载清理后的 PDF 文件。
优点
- 无需安装任何软件
- 适用于所有操作系统
- 适合一次性或偶尔使用的任务
缺点
- 文件大小和使用次数受限
- 存在隐私和安全风险
- 不适合处理机密或敏感文档
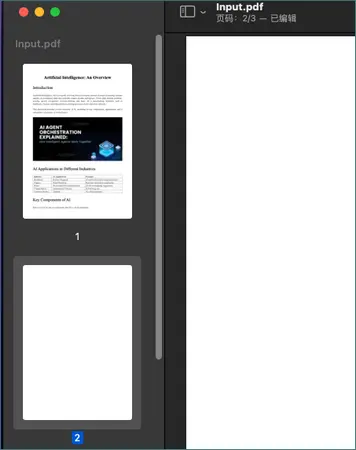
方法 3:通过预览(macOS)删除空白页
macOS 自带的预览应用支持基本的 PDF 编辑功能,包括删除页面。它是 macOS 用户的一个简单且免费的选择。
详细步骤
- 使用预览打开 PDF 文件。
- 选择“显示”→“缩略图”,启用缩略图侧边栏。
- 在缩略图面板中选择空白页。
- 按下键盘上的“Delete”键。
- 保存修改后的 PDF。

优点
- macOS 预装的免费应用
- 离线使用,操作简单
- 无需第三方工具
缺点
- 仅适用于 macOS
- 手动操作,无法扩展
- 高级 PDF 功能有限
何时手动方法已不再适用
在以下场景中,手动方法会变得低效:
- 需要处理大量 PDF 文件
- 清理自动生成的报告
- 执行重复性的文档维护任务
- 将 PDF 清理集成到应用或服务中
在这些情况下,自动化是最实用且可靠的选择。
第 2 部分:使用 Python 自动删除 PDF 中的空白页
自动化可以在无需人工干预的情况下,高效且一致地删除空白页。由于其简洁性、跨平台支持以及丰富的库生态,Python 特别适合用于此类任务。
为什么使用 Python 进行 PDF 自动化?
借助 Python,你可以:
- 以编程方式处理 PDF
- 处理大文件和批量操作
- 将 PDF 清理集成到后端系统
- 在不同文档中保持一致的检测逻辑
自动化可以显著减少人工操作,并降低人为错误的风险。
Spire.PDF for Python 简介
Spire.PDF for Python 是一个功能强大的 PDF 创建、编辑和处理库。它提供了对 PDF 结构和内容的精细控制,非常适合用于空白页检测和删除等任务。
在本解决方案中,Spire.PDF 提供了:
- 页面级访问
- 内置空白页检测
- PDF 转图像功能
- 安全的页面删除机制
示例:自动检测并删除 PDF 中的空白页
下面是一个使用 Spire.PDF for Python 和 Pillow(PIL)的完整 Python 示例。
1 | import io |
本方案中的空白页检测原理
为了提高准确性,该方案结合了两种互补的检测方法:
- 逻辑检测 :脚本首先使用 page.IsBlank() 判断页面在逻辑上是否为空,即是否不包含文本或图像对象。
- 视觉检测 :如果页面在逻辑上不为空,则将其转换为图像并逐像素分析。如果所有像素均为白色,则该页面在视觉上被视为空白页。
这种组合策略可以同时删除技术上为空的页面,以及包含隐藏内容但在视觉上为空白的页面。
延伸阅读:使用 Python 查找并删除 PDF 文件中的空白页
扩展自动化解决方案
该脚本可以轻松扩展,用于:
- 处理目录中的所有 PDF 文件
- 作为定时清理任务运行
- 集成到文档管理系统中
- 记录被删除的页面,用于审计或调试
稍作调整后,它即可支持企业级的 PDF 工作流。如需执行更高级的 PDF 操作(例如文本提取、页面操作或内容分析),可参考 Spire.PDF 编程指南,以进一步扩展和定制自动化逻辑。
手动 vs 自动化空白页删除
| 对比维度 | 手动方式 | Python 自动化 |
|---|---|---|
| 易用性 | 高 | 中 |
| 准确性 | 高 | 高 |
| 批量处理 | 不支持 | 支持 |
| 可扩展性 | 不支持 | 支持 |
| 最佳适用场景 | 小型 PDF 文件 | 大规模或重复性任务 |
删除 PDF 空白页的最佳实践
- 在删除空白页前先备份 PDF,以防误删页面并便于快速恢复。
- 在批量或正式处理前,通过测试不同类型的 PDF 验证空白页识别的准确性。
- 扫描 PDF 通常包含图像或噪点,可能导致误判,需特别注意。
- 对重要文档建议在自动删除后进行人工复核,确保内容安全。
总结
删除 PDF 中的空白页虽是一个小步骤,却是生成整洁、专业文档的重要环节。手动方法适用于快速修改和小文件,但在规模化场景中效率有限。
对于大规模或重复性任务,自动化是更优选择。通过使用 Spire.PDF for Python 并结合逻辑与视觉检测技术,你可以可靠地删除技术上和视觉上的空白页。该方案能够节省时间、提升一致性,并无缝集成到现代文档工作流中。
FAQs
Q1:为什么 PDF 文件中会出现空白页或多余页面?
空白页或多余页面通常源于文档转换过程中的格式问题、不正确的分页符、扫描伪影,或从 Word、Excel 及报表工具导出文件时产生的问题。
Q2:不使用付费软件也可以删除 PDF 页面吗?
可以。你可以使用 macOS Preview 等内置工具、在线 PDF 编辑器,或支持基础页面管理功能的免费桌面 PDF 阅读器来删除页面。
Q3:删除页面会影响剩余 PDF 的内容或布局吗?
删除页面不会改变剩余页面的布局或格式。但建议在操作后检查文档,以确保页码、书签或引用仍然合理。
Q4:删除 PDF 页面是否安全?
是的,只要你保留原始文件的备份即可。将删除页面后的结果另存为新文件是一种非破坏性操作,必要时可以轻松恢复原文件。




