从受保护的 PDF 中复制文本:5 种免费方法
从受保护的 PDF 中复制文本:5 种免费方法
PDF 文件因其能在不同设备上保持布局和格式而被广泛用于共享文档。然而,有些PDF文件设置了安全权限,阻止用户复制文本。当你尝试选择或复制这些文件中的内容时,可能会发现复制功能被禁用了。
这类文件通常被称为受保护的、或受限的 PDF。与需要密码才能打开的加密PDF不同,这些文档可以正常查看,但某些操作(如复制文本)受到了限制。
幸运的是,有几种免费且实用的变通方法可以帮助你从受保护的 PDF 中提取或复制文本 。在本指南中,我们将探讨五种简便方法,包括在线工具、系统内置功能以及 Python 自动化方法。
快速导航
- 方法一:使用谷歌文档从受保护的PDF中复制文本
- 方法二:在线将受限 PDF 转换为TXT
- 方法三:截图 + OCR 提取文本
- 方法四:将防复制 PDF 打印成新的 PDF
- 方法五:使用 Python 从受保护的 PDF 中提取文本
为什么无法从有些 PDF 文件复制文本?
许多 PDF 创建者会应用权限限制来控制文档的使用方式。这些权限在 PDF 的安全设置中设定,可能会禁用以下操作:
- 复制文本
- 编辑文档
- 打印文件
- 添加注释
这通常被称为复制保护或内容限制 。虽然文档仍然可读,但 PDF 阅读器会阻止文本选择或复制。
这些限制通常用于保护知识产权或防止未经授权的内容重用。然而,当你出于合法需要重用文本时——例如用于研究、文档编制或辅助功能——你可能需要其他方法来提取内容。
以下五种方法可以帮到你。
方法一:使用谷歌文档从受保护的PDF 中复制文本
从受保护的 PDF 中复制文本最简单的方法之一是用谷歌文档打开它。当 PDF 上传到谷歌云端硬盘并在谷歌文档中打开时,该服务会自动将文件转换为可编辑的文档。
在此转换过程中,PDF 的内容会被重新解析为文本和段落,这通常可以绕过基本的复制限制。转换完成后,你就可以像在普通文档中一样轻松选择和复制文本了。
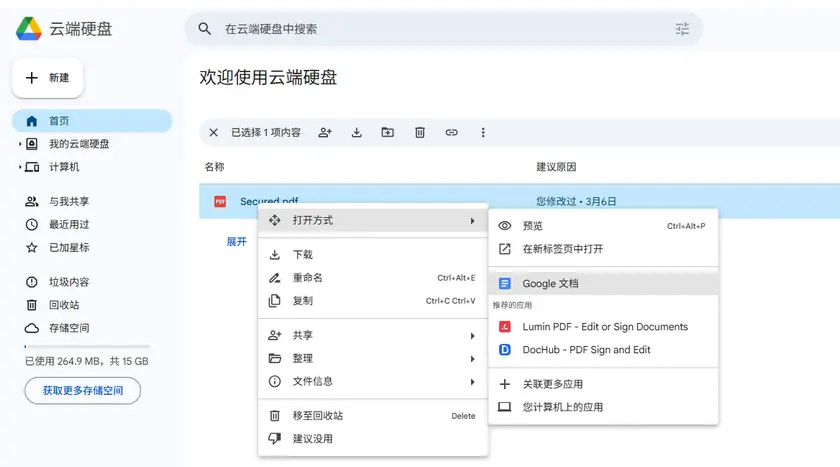
步骤
- 打开云端硬盘 。
- 上传受保护的 PDF。
- 右键单击该文件,选择打开方式 → Google文档 。
- 谷歌文档会将 PDF 转换为可编辑的文档。
- 从文档中复制提取出的文本。
优点
- 免费且易于使用。
- 无需安装软件。
- 对于基于文本的文档效果很好。
局限性
- 扫描件或基于图像的 PDF 无法转换为文本(不支持 OCR)。
- 复杂布局的格式可能会混乱。
- 需要谷歌账户和网络连接。
方法二:在线将受限PDF 转换为TXT
另一个快速的解决方案是使用在线转换器将受限的 PDF 转换为纯文本文件。一旦文档转换为 TXT 格式,文本就变得完全可编辑,并且可以无限制地复制。
一个方便好用的免费工具是 PDF24,它提供了一个基于浏览器的 PDF 转 TXT 转换器 。当你需要在不安装额外软件的情况下快速提取文本时,此方法很有效。
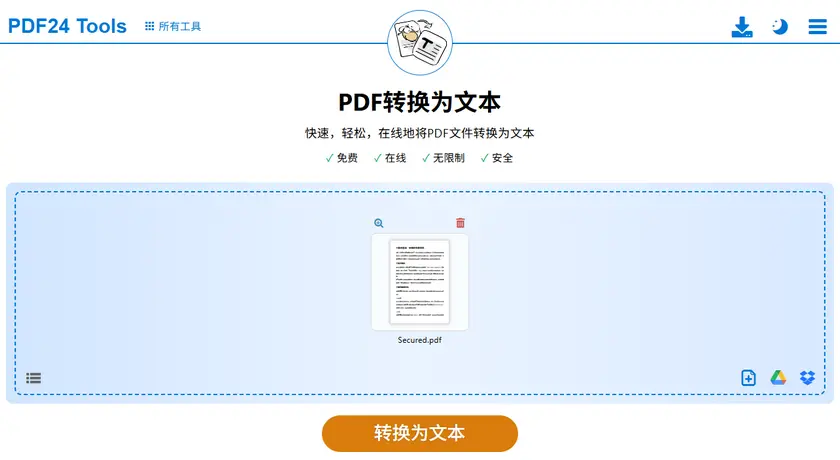
步骤
- 打开 PDF 转 TXT 工具。
- 上传你的受保护 PDF 文件。
- 开始转换过程。
- 下载生成的 TXT 文件。
- 打开 TXT 文件,自由复制文本。
优点
- 快速简便的操作流程。
- 无需安装。
局限性
- 隐私风险——敏感文档上传至第三方服务器。
- 通常每天只有几次免费转换的限制。
- 大多数免费工具不支持 OCR (基于图像的 PDF 将无法转换)。
方法三:截图 + OCR 提取文本
如果 PDF 具有严格的复制限制或包含扫描页面, OCR (光学字符识别) 技术仍然可以提取出可见的文本。OCR 技术分析文档的图像,并将检测到的字符转换为可编辑的文本。
Windows 11 的 截图工具 内置了 OCR 功能,允许你捕获屏幕的一部分并立即从图像中提取文本。
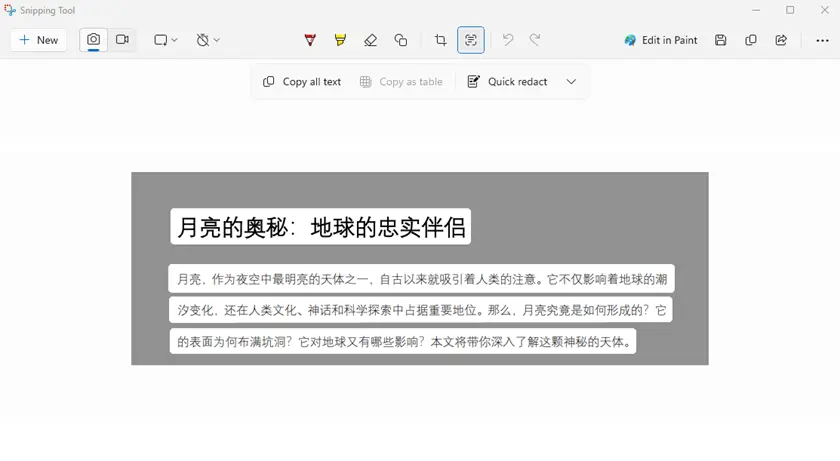
步骤
- 在屏幕上打开受保护的 PDF。
- 启动截图工具 。
- 捕获包含文本的区域。
- 使用文本操作 → 复制所有文本 。
- 将提取的文本粘贴到文档中。
优点
- 通过截取屏幕,几乎可以绕过所有复制保护。
- 适用于扫描件或基于图像的 PDF。
局限性
- 如果页数多,会很耗时。
- OCR 错误——准确性取决于图像质量和字体。
- 除非使用脚本自动化,否则是手动过程。
方法四:将防复制PDF 打印成新的PDF
一些受保护的 PDF 阻止复制,但允许打印。在这种情况下,你可以将文档打印成一个新的 PDF 文件,这可能会移除复制限制。
使用谷歌 Chrome 浏览器内置的打印功能可以轻松完成此操作。保存文件的打印版本后,新的 PDF 文件可能允许正常的文本选择和复制。
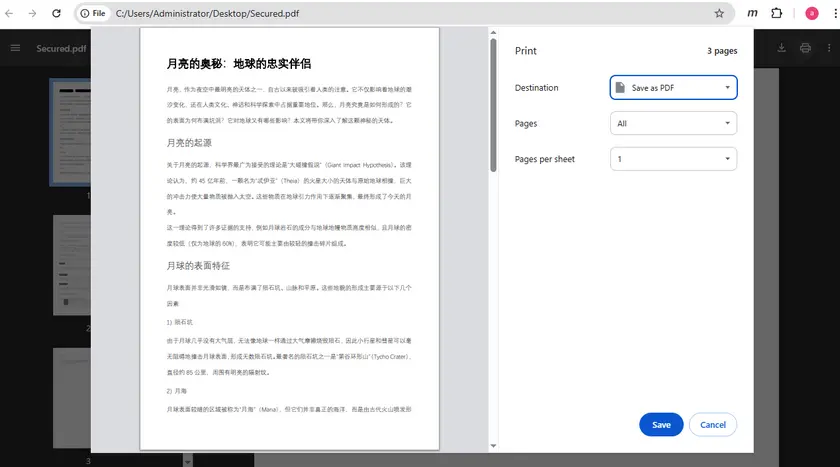
步骤
- 在谷歌 Chrome 浏览器中打开 PDF。
- 按 Ctrl + P 打开打印对话框。
- 将目标打印机设置为另存为 PDF 。
- 保存新生成的 PDF。
- 打开新文件并尝试复制文本。
优点
- 简单的变通方法。
- 无需额外工具。
局限性
- 如果 PDF 权限中禁用了打印功能,此方法无效。
- 可能会出现一些格式差异。
方法五:使用Python 从受保护的PDF 中提取文本
对于需要处理多个文档的开发者或用户来说,通过编程方式提取文本可能是最有效的解决方案。无需手动复制内容,脚本可以自动读取PDF结构并从每个页面检索文本。
使用 Free Spire.PDF for Python,你只需几行代码就能轻松从 PDF 文档中提取文本。这种方法对于自动化、批量处理或构建文档处理工作流特别有用。
如果你处理的是小文档(每个文档10页以内)或测试提取流程,免费版本就很好用。对于较大的文件,你可以先拆分文档,或者使用[完整版。
安装库
1 | pip install spire.pdf.free |
示例:从每一页提取文本
1 | from spire.pdf import * |
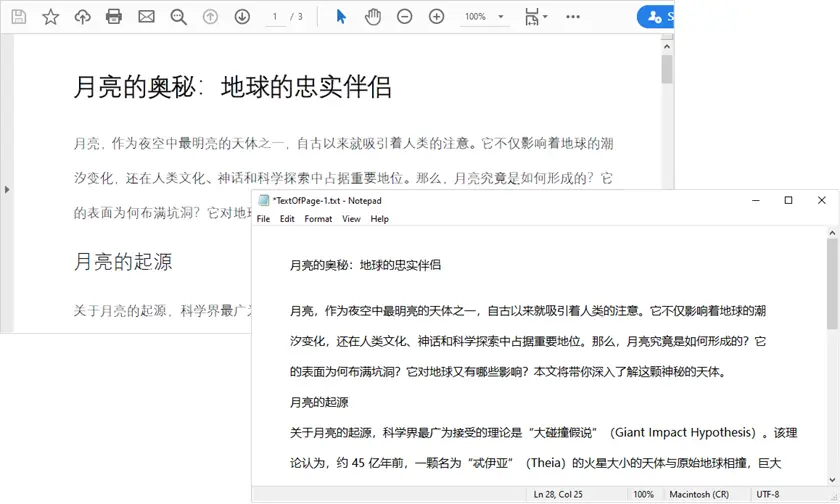
此脚本的作用
- 加载 PDF 文档。
- 遍历每一页。
- 提取文本,同时保留空白。
- 将提取的文本保存到 TXT 文件中。
优点
- 完全控制提取过程。
- 可以自动化进行批量处理。
- 对于基于文本的 PDF 效果很好。
局限性
- 需要编程知识。
- 无法处理基于图像的PDF,除非使用额外的OCR库。
你可能还喜欢: 如何使用 Python 从图片中提取文字(OCR 代码示例)
对比表格:你应该选择哪种方法?
| 方法 | 技能水平 | 易用性 | 最适合的场景 | 是否适用于扫描件 | 在严格限制下是否有效 | 是否支持批量处理 |
|---|---|---|---|---|---|---|
| 谷歌文档 | 初学者 | 非常简单 | 在浏览器中快速提取 | 否 | 是 | 否 |
| 在线转换器 | 初学者 | 非常简单 | 快速转换为TXT | 否 | 是 | 否 |
| 截图 + OCR | 初学者 | 简单 | 扫描件或基于图像的PDF | 是 | 是 | 否 |
| 打印为 PDF | 初学者 | 简单 | 移除简单的复制限制 | 否 | 有条件(必须允许打印) | 否 |
| Python (Free Spire.PDF) | 开发者 | 中等 | 自动化及批量处理工作流 | 需依赖额外OCR库 | 是 | 是 |
结论
PDF 中的复制限制可能令人沮丧,尤其是在你只需要重用部分文本时。幸运的是,有几种免费方法可以帮助你从受保护的 PDF 中提取内容。
对于快速任务,像谷歌文档或在线转换器这样的工具可能是最简单的解决方案。如果文档包含扫描内容或有严格限制,基于 OCR 的方法仍然可以恢复文本。对于大规模工作流或自动化场景,使用像 Free Spire.PDF for Python 这样的 Python 库提供了一种强大而灵活的方法。
通过选择最适合你需求的方法,你可以高效地从受限 PDF 中检索文本,同时保持高效的工作流程。
常见问题解答
什么是受保护或受限的 PDF?
受保护或受限的 PDF 是一种可以正常打开和查看的文档,但其安全设置阻止了复制、打印或编辑其内容。这些权限由文档所有者设置。
我可以从所有受保护的 PDF 中复制文本吗?
不一定。有些 PDF 具有强加密或 DRM(数字版权管理)保护,完全阻止复制。在这种情况下,可能需要使用
OCR 工具或专业库。
哪种方法最适合扫描的 PDF ?
对于扫描的 PDF,截图+OCR 提取或使用带有 OCR 库的 Python 自动化通常是检索文本最可靠的方法。
我可以自动化提取多个 PDF 的文本吗?
可以。使用像 Spire.PDF 这样的 Python 库,你可以自动从多个 PDF 文件中提取文本,非常适合批量处理或工作流自动化。
我需要为这些方法付费吗?
文章中列出的所有方法都是免费的。但是,有些工具(如 Spire.PDF)的免费版本有局限性,例如页面数量限制。对于较大的文件,你可能需要使用完整版。